Text Recognition with ML Kit
See how to use the new ML Kit library from Google to use machine learning and computer vision to perform text recognition in an image. By Victoria Gonda.
Enabling Firebase for in-cloud text recognition
There are a couple of extra steps to complete in order to run text recognition in the cloud. You’ll do this now, as it takes a couple minutes to propagate and be usable on your device. It should then be ready for when you get to that part of the tutorial.
On the Firebase console for your project, ensure you’re on the Blaze plan instead of the default Spark plan. Click on the plan information in the bottom left corner of the screen to change it.

You’ll need to enter payment information for Firebase to proceed with the Blaze plan. Don’t worry, the first 1000 requests are free, so you don’t have to pay towards it over the course of following this tutorial. You can switch back to the free Spark plan when you’ve finished the tutorial.
If you’re hesitant to put in payment information, you can just stick with the Spark plan while following the on-device steps in the remainder of the tutorial, and then just skip over the instruction steps below for using ML Kit in the cloud. :]

Next, you need to enable the Cloud Vision API. Choose ML Kit in the console menu at the left.

Next, choose Cloud API Usage on the resulting screen.

This takes you to the Cloud Vision API screen. Make sure to select your project at the top, and click the Enable button.

In a few minutes, you’ll be able to run your text recognition in the cloud!
Detecting text on-device
Now you get to dig into the code! You’ll start by adding functionality to detect text in the image on-device.
You have the option to run text recognition on both the device and in the cloud, and this flexibility allows you to use what is best for the situation. If there’s no network connectivity, or you’re dealing with sensitive data, running the model on-device might be better.
In MainActivityPresenter.kt, find the runTextRecognition() method to fill in. Add this code to the body of runTextRecognition(). Use Alt + Enter on PC or Option + Return on a Mac to import any missing dependencies.
view.showProgress()
val image = FirebaseVisionImage.fromBitmap(selectedImage)
val detector = FirebaseVision.getInstance().visionTextDetector
This starts by signaling to the view to show the progress so you have a visual queue that work is being done. Then you instantiate two objects, a FirebaseVisionImage from the bitmap passed in, and a FirebaseVisionTextDetector that you can use to detect the text.
Now you can use that detector to detect the text in the image. Add the following code to the same runTextRecognition() method below the code you added previously. There is one method call, processTextRecognitionResult() that is not implemented yet, and will show an error because of it. Don’t worry, you’ll implement that next.
detector.detectInImage(image)
.addOnSuccessListener { texts ->
processTextRecognitionResult(texts)
}
.addOnFailureListener { e ->
// Task failed with an exception
e.printStackTrace()
}
Using the detector, you detect the text by passing in the image. The method detectInImage() takes two callbacks, one for success, and one for error. In the success callback, you have that method you still need to implement.
Once you have the results, you need to use them. Create the following method:
private fun processTextRecognitionResult(texts: FirebaseVisionText) {
view.hideProgress()
val blocks = texts.blocks
if (blocks.size == 0) {
view.showNoTextMessage()
return
}
}
At the start of this method you tell the view to stop showing the progress, and do a check to see if there is any text to process by checking the size of the text blocks property.
Once you know you have text, you can do something with it. Add the following to the bottom of the processTextRecognitionResult() method:
blocks.forEach { block ->
block.lines.forEach { line ->
line.elements.forEach { element ->
if (looksLikeHandle(element.text)) {
view.showHandle(element.text, element.boundingBox)
}
}
}
}
The results come back as a nested structure so you can look at it in whatever kind of granularity you want. The hierarchy for on-device recognition is block > line > element > text. You iterate through each of these, check to see if it looks like a Twitter handle, using a regular expression in a helper method looksLikeHandle(), and show it if it does. Each of these elements have a boundingBox for where ML Kit found the text in the image. This is what the app uses to draw a box around where each detected handle is.
Now build and run the app, select an image containing Twitter handles, and see the results! If you tap on one of these results, it will open the Twitter profile. :]
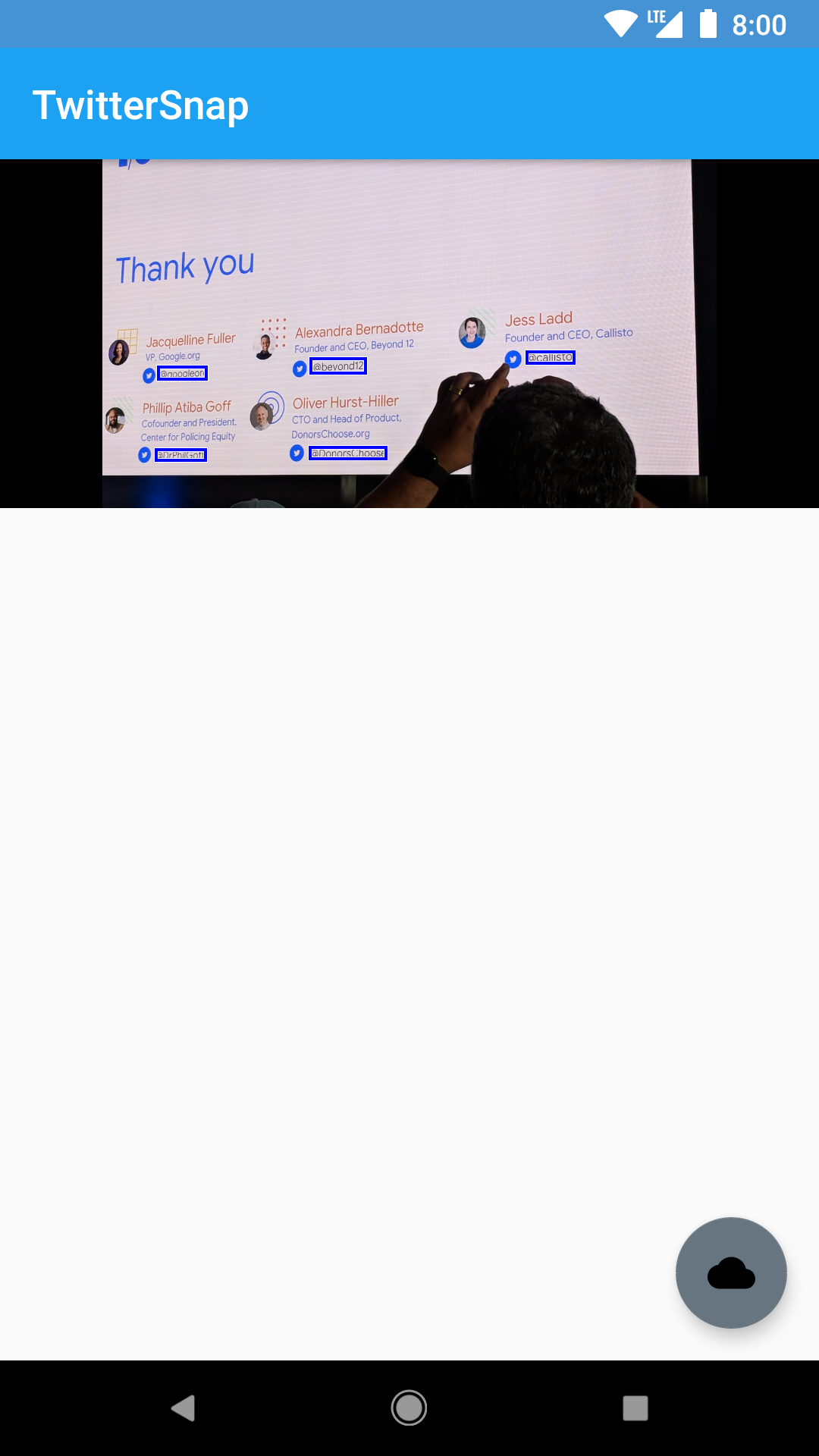
You can click the above screenshot to see it full size and verify that the bounding boxes are surrounding Twitter handles. :]
As a bonus, the view also has a generic showBox(boundingBox: Rect?) method. You can use this at any stage of the loop to show the outline of any of these groups. For example, in the line forEach, you can call view.showBox(line.boundingBox) to show boxes for all the lines found. Here’s what it would look like if you did that with the line element:

Detecting text in the cloud
After you run the on-device text recognition, you may have noticed that the image on the FAB changes to a cloud icon. This is what you’ll tap to run the in-cloud text recognition. Time to make that button do some work!
When running text recognition in the cloud, you receive more detailed and accurate predictions. You also avoid doing all that extra processing on-device, saving some of that power. Make sure you completed the Enabling Firebase for in-cloud text recognition section above so you can get started.
The first method you’ll implement is very similar to what you did for the on-device recognition. Add the following code to the runCloudTextRecognition() method:
view.showProgress()
// 1
val options = FirebaseVisionCloudDetectorOptions.Builder()
.setModelType(FirebaseVisionCloudDetectorOptions.LATEST_MODEL)
.setMaxResults(15)
.build()
val image = FirebaseVisionImage.fromBitmap(selectedImage)
// 2
val detector = FirebaseVision.getInstance()
.getVisionCloudDocumentTextDetector(options)
detector.detectInImage(image)
.addOnSuccessListener { texts ->
processCloudTextRecognitionResult(texts)
}
.addOnFailureListener { e ->
e.printStackTrace()
}
There are a couple small differences from what you did for on-device recognition.
- The first is that you’re including some extra options to your detector. Building these options using a
FirebaseVisionCloudDetectorOptionsbuilder, you’re saying that you want the latest model, and to limit the results to 15. - When you request a detector, you are also specifying that you want a
FirebaseVisionCloudTextDetector, which you pass those options to. You handle the success and failure cases in the same way as on-device.
You will be processing the results similar to before, but diving in a little deeper using information that comes back from the in-cloud processing. Add the following nested class and helper functions to the presenter:
class WordPair(val word: String, val handle: FirebaseVisionCloudText.Word)
private fun processCloudTextRecognitionResult(text: FirebaseVisionCloudText?) {
view.hideProgress()
if (text == null) {
view.showNoTextMessage()
return
}
text.pages.forEach { page ->
page.blocks.forEach { block ->
block.paragraphs.forEach { paragraph ->
paragraph.words
.zipWithNext { a, b ->
// 1
val word = wordToString(a) + wordToString(b)
// 2
WordPair(word, b)
}
.filter { looksLikeHandle(it.word) }
.forEach {
// 3
view.showHandle(it.word, it.handle.boundingBox)
}
}
}
}
}
private fun wordToString(
word: FirebaseVisionCloudText.Word): String =
word.symbols.joinToString("") { it.text }
If you look at the results, you’ll notice something. The structure of the text recognition result is slightly different than when it runs on the cloud. The accuracy of the cloud model can provide us with some more detailed information we didn’t have before. The hierarchy you’ll see is page > block > paragraph > word > symbol. Because of this, we need to do a little extra to process it.
- With the granularity of the results the “@” and the other characters of a handle are is separate words. Because of that, you are taking each word, creating a string from it using the symbols in
wordToString(), and concatenating each neighboring word. - The new class you see,
WordPair, is a way to give names to the pair of objects, the string you just created, and the Firebase object for the handle. - From there, you are displaying it the same as the on-device code.
Build and run the project, and test it out! After you pick an image, and run the recognition on the device, click the cloud icon in the bottom corner to run the recognition in the cloud. You may see results that the on-device recognition missed!

Again, you can use showBox(boundingBox: Rect?) at any level of the loops to see what this level detects. This has boxes around every paragraph:
